Voyager and the Art of Graceful Degradation
Like a great celestial swan, Voyager 1 is flying — swiftly, boldly, albeit a little stiffly in places.
 |
| NASA/JPL-Caltech |
It moves through interstellar space with enormous momentum, far beyond the planets that once defined its mission, carrying instruments that continue to report from a region no man‑made craft has ever reached. Yet every action it takes is constrained by a finite and steadily diminishing supply of energy, each signal carefully weighed against what it costs to send.
There is a quiet elegance in that balance.
Voyager does not insist on doing everything it once did. It does not pursue peak capability when conditions no longer allow it. Instead, it adapts -- releasing some functions so that others can continue, prioritizing what matters most over what is merely possible.
In engineering, we have a name for systems that behave this way.
We call it graceful degradation.
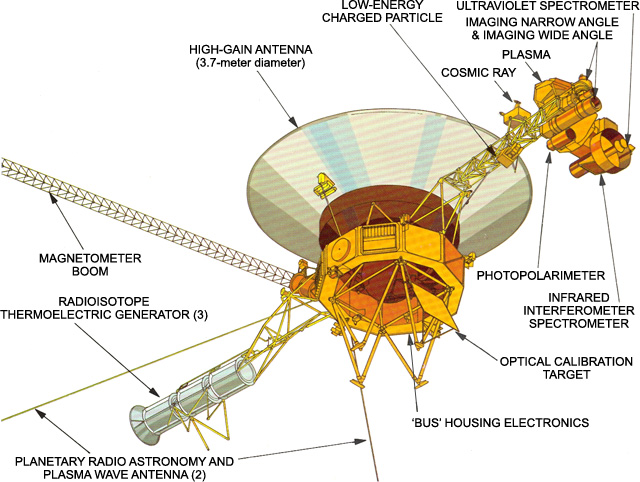
Voyager is powered by a radioisotope thermoelectric generator whose output declines as radioactive fuel decays. Every year, available power drops by a few watts. Unlike systems here on Earth, there is no possibility of provisioning more capacity, no redundancy waiting in reserve, and no “scale out” option.
Seen through a Site Reliability Engineering lens, Voyager’s power margin is its error budget. It defines how much can go wrong before the mission begins to suffer.
Early in the mission, that budget was generous. Minor inefficiencies, unexpected behaviors, and non‑optimal configurations could be tolerated. As the decades passed, the margin narrowed. Today, even a modest, unplanned dip of power by a wayward instrument risks triggering Voyager’s undervoltage fault protection — an automated safeguard that will shut components down abruptly to ensure survival.
In February, a routine roll maneuver caused such a dip. Engineers understood that allowing the spacecraft to cross that line would mean entering a survival mode where system preservation is prioritized over delivering mission value.
This moment is familiar to anyone who has operated a production system near its limits:
- CPU saturation turning latency into user-visible slowness
- Memory pressure triggering process and container termination
- Queues backing up until messages expire undelivered
- Storage exhaustion freezing otherwise healthy transactions
Graceful degradation is about prioritizing your goals and your capabilities, and as you approach a point where you cannot fulfill all your goals, acting before you reach that point.
- Reduce CPU consumption (lower frame rates, remove animations, disable optional features)
- Defer low‑priority work (batch reports, replace live data with aggregates)
- Prioritize critical traffic and drop nonessential messages
- Reject new transactions when storage thresholds are reached to protect core paths
In Reliability Engineering, as in much of life, we'd rather have brownouts than blackouts.
While we never want to disappoint users, we'd rather reduce features rather than take outages. We'll degrade experience -in a controlled fashion - rather than lose the service entirely. We shed load in controlled ways instead of letting cascading failures decide the outcome.
That is exactly what Voyager’s engineers did.
Years before this moment, scientists and engineers jointly agreed on a shutdown sequence: which instruments would be sacrificed first as power declined, and which capabilities were most critical to preserve. By April 2026, seven of Voyager 1’s ten original science instruments had already been retired. The LECP was simply next on the list — not because it failed, but because its cost‑to‑value ratio was now unfavorable.
This is the same decision Site Reliability Engineers (SREs) make when:
- Disabling expensive recommendation pipelines during peak traffic
- Serving cached or approximate results instead of fully computed ones
- Temporarily turning off background jobs to protect user‑facing latency
Nothing is broken, per se. The system is deliberately choosing to do less so that it can continue to succeed in part rather than fail in total. Graceful degradation is not a weakness; it is a sign of maturity.
Voyager continues to operate the instruments that provide uniquely valuable data — measuring magnetic fields and plasma waves in interstellar space — while relinquishing others whose contribution, though still useful, no longer justifies their cost.
Even the LECP shutdown was reversible by design. A small motor that rotates the sensor remains powered, preserving the option of reactivation should future power‑saving measures succeed.
This is graceful degradation with reversibility in mind. The current state is preserved, while recovery paths maintained and, most importantly, options are left open. Granted, the chances of Voyager suddenly being replenished with fresh plutonium for additional power is exactly 0, but Reliability Engineers here on the ground do plan on overcoming their temporary issues which caused the degradation and using the available options to fully restore services.
This is why we gate features behind flags instead of deleting code and why we can temporarily change users' capabilities instead of removing them from the system.
Balancing Performance, Capacity, and Risk
Reliability is rarely about maximizing performance. It is about continuously balancing performance, capacity, and risk — especially when capacity is finite and margins are thin.
Voyager operates permanently at this intersection.
Performance, in Voyager’s case, is scientific throughput: how many instruments are active, how often measurements are taken, and how much data is returned.
Capacity is a steadily shrinking power budget that cannot be replenished.
Risk grows as margins shrink: a sudden undervoltage event could trigger autonomous shutdowns that are difficult, slow, and dangerous to recover from across a 23‑hour communication delay.
Graceful degradation is how the Voyager team manages this triangle.
By shutting down the LECP before power levels became critical, the team deliberately traded peak scientific performance for reduced operational risk and preserved capacity for the instruments that matter most.
 |
| The status of Voyager's instruments (NASA/JPL-Caltech) |
Voyager does less than it once did — but it does so more safely, more predictably, and for longer.
This mirrors everyday SRE work:
- lowering request concurrency to prevent saturation
- reducing image quality or refresh rates under load
- shrinking feature scope during high-risk windows
- renegotiating SLOs instead of pretending nothing has changed
In each case, performance is intentionally reduced to keep risk within acceptable bounds.
Because Voyager’s degradation path was defined years in advance, with a healthy system and with management & engineering having time and clarity to make rational trade-offs, the unexpected power dip didn't result in a frantic rush to heroically solve a problem, it triggered a pre-planned process which resulted in a graceful retirement of the instrument chosen ahead of time. No surprises, just good engineering.
Graceful degradation is a social and organizational capability as much as a technical one. It requires shared understanding across teams, explicit agreement on priorities, and acceptance that loss is inevitable. It's not about preventing failure forever. It is about ensuring that when degradation occurs, it happens on your terms.
While few of us work on systems like Voyager, there are many commonalities -
- Our platforms are usually far older than the original business model they were designed to support.
- Our architectures often outlast our architects.
- Our "temporary" services that we built with “temporary” design decisions have become permanent.
Our systems survive not by staying perfect, but by letting go gracefully. At least, these are the ones which cause the least stress to their owners and maintainers.
Voyager is still returning data from interstellar space not because nothing has failed, but because failures have been managed thoughtfully, incrementally, and with humility. Twenty-five billion kilometers from Earth, Voyager continues to demonstrate a lesson every experienced SRE eventually learns:
The systems that last longest are not the ones that cling to every feature, but the ones that decide, and well in advance, which parts they are willing to give up.


Comments
Post a Comment